
UCSC Lab 12
ANOVA (One-Way)
PURPOSE
- Understand the null hypothesis in terms of Type I and Type II errors
- Learn how to perform and interpret an ANOVA test for significance
- Learn how to interpret confidence intervals
- Gain further insight into results of crosstabulations
MAIN POINTS
Types of Error, the null hypothesis and statistical significance
- Researchers often distinguish Type I and II errors.
- Type I occurs when we conclude that there is a relationship between two variables when there is actually none (a false positive).
- Type II occurs when we conclude that there is no relationship between two variables when one exists in reality (a false negative).
| REALITY | |||
| No Relationship | Relationship | ||
| ANALYTICAL CONCLUSION | No Relationship | accurate | Type II Error |
| Relationship | Type I Error | accurate | |
- Researchers routinely take the null hypothesis of no relationship between variables as the basis for their work.
- Measures of significance are used to rule out the null hypothesis and avoid making Type I errors.
- A significance or probability level indicates the percentage chance of making a Type I Error.
- Probabilities of .05 and less are conventionally taken as grounds for ruling out the null hypothesis and concluding a relationship does exist.
One-way ANOVA
- One-way ANOVA: ANalysis Of VAriance.
- One-way Anova is used to see whether the mean of the dependent variable differs across categories of an independent (group) variable.
- The independent variable used in an ANOVA test can have 3 or more categories and may be nominal or ordinal. The dependent variable is ideally an interval variable.
- Anova can also be used with an ordinal dependent variable, particularly one with many values such as we have using an un-recoded (raw) index.
- Anova produces an F statistic which measures the ratio of between-group variation to within-group variation.
- The higher the value of F, the more likely the difference between the means is significant, i.e., not due to chance.
- An F score is compared to a probability distribution to arrive at the probability (p) value.
- Probability levels for F are interpreted in the same way as those for Chi-square.
EXAMPLE #1 — Conventional Use of ANOVA
- Dataset:
- ANES 2012
- Hypothesis Arrow Diagram:
- Party ID → Economic Egalitarianism
- Syntax
*Identifying EconEq Index Items*. weight by weight_full. missing values cses_govtact (-9 thru -6). recode cses_govtact (1=1) (2=.75) (3= .5) (4= .25) (5=0) into eceq1. missing values ineqinc_ineqreduc (-9 thru -6). recode ineqinc_ineqreduc (1=1) (2=0) (3= .5) into eceq3. missing values guarpr_self (-9 thru -2). recode guarpr_self (1=1) (2=.832) (3= .666) (4= .5) (5= .332) (6= .166) (7=0) into eceq5. *Constructing the Index*. compute RawEqIndex = eceq1 + eceq3 + eceq5. *Recoding the Index*. recode RawIndex (.00 thru 1.00 =1) (1.01 thru 1.85 =2) (1.86 thru 3 = 3) into IEcEq3. *Creating an IV*. missing values pid_self (-9 thru 0, 5). missing values pid_x (-2). recode pid_self (1=1) (3 = .5) (2=0) into pid. value labels pid 1 'Dem' .5 'Ind' 0 'Rep'. *One-way ANOVA*. oneway RawEqIndex by pid /statistics=descriptives /ranges=scheffe /plot means.
- Syntax Legend
- Missing values and recodes are specified as usual
- The oneway (anova) command lists the DV followed by IV
- The optional /ranges=scheffe subcommand produces a table indicating which groups differ significantly
- The optional /plot means command produces a graphic showing the mean score on the DV for each group defined by the IV.
- Output
Descriptives
| N | Mean | Std. Dev | Std. Error | 95% Confidence Interval | ||
| Lower Bound | Upper Bound | |||||
| Repub | 1402 | .8026 | .76980 | .02056 | .7622 | .8429 |
| Indep | 1629 | 1.3302 | .81743 | .02025 | 1.2905 | 1.3699 |
| Democ | 1746 | 1.7765 | .65396 | .01565 | 1.7458 | 1.8072 |
| Total | 4777 | 1.3385 | .84400 | .01221 | 1.3145 | 1.3624 |
| ANOVA | |||||
| raweqindex | |||||
| Sum of Squares | df | Mean Square | F | Sig. | |
| Between Groups | 737.841 | 2 | 368.920 | 661.015 | .000 |
| Within Groups | 2664.427 | 4774 | .558 | ||
| Total | 3402.267 | 4776 | |||
| Multiple Comparisons | ||||||
| Dependent Variable: raweqindex | ||||||
| Scheffe | ||||||
| (I) PID4 | (J) PID4 | Mean Difference (I-J) | Std. Error | Sig. | 95% Confidence Interval | |
| Lower Bound | Upper Bound | |||||
| Rep | Ind | -.52766* | .02721 | .000 | -.5943 | -.4610 |
| Dem | -.97396* | .02679 | .000 | -1.0396 | -.9084 | |
| Ind | Rep | .52766* | .02721 | .000 | .4610 | .5943 |
| Dem | -.44631* | .02573 | .000 | -.5093 | -.3833 | |
| Dem | Rep | .97396* | .02679 | .000 | .9084 | 1.0396 |
| Ind | .44631* | .02573 | .000 | .3833 | .5093 | |
| *. The mean difference is significant at the .050 level. | ||||||
Means Plot
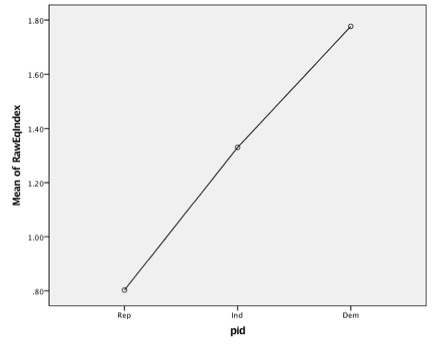
- Interpretation
- The Descriptives panel shows the mean scores on the DV for each category of the IV plus information on the confidence intervals around the means and their calculation.
- The ANOVA panel contains the F-score and its associated significance level for the analysis. The .000 significance means that there is less than a 1 in 1000 chance that the observed mean differences on the egalitarian index are due simply to sampling error. Thus, there is a significant difference in egalitarian attitudes across partisan groups.
- The Multiple Comparisons panel calculates the mean difference between each pair of groups and uses information from the Descriptives panel to calculate which pairs of groups differ significantly from one another.
- The Means Plot proves a graphic depiction of the mean differences in Egalitarian attitudes across Partisan groups.
INSTRUCTIONS
- Using your index from Lab 9, hypothesize a relationship between it and an independent variable
- For example, egalitarian attitudes should vary with Party Identification.
- The independent (group) variable should have three or more categories and preferably be nominal, although it can be ordinal.
- The dependent variable should ideally be interval, although you can use an ordinal variable with multiple categories.
- Make Frequency runs for each of the variables to identify missing values and recodes.
- Perform a One-way ANOVA
- specify the DV first, then the IV
- include a statistics subcommand for descriptives
- request a scheffe test on the ranges subcommand
- ask for means to be plotted.
- Based on the output, determine whether differences in the means on the dependent variable across the categories of the independent (group) variable are likely due to sampling error, or are representative of the population. Make this judgment using the .05 significance level.
- Repeat the steps above until you find a pair of variables that yield significant results for the ANOVA test.
QUESTIONS FOR REFLECTION
- Did you find a significant result? If so, what is the likelihood that you are making a Type I Error?
- How does One-way ANOVA differ from a chi-square?
DISCUSSION
- Recall that the measure of significance represents the likelihood of making a Type I error. So if sig.=.03, then the likelihood that you are making a Type I error (concluding there is a relationship, when there is none) is 3 in 100.
- The chi-square assesses significance in a crosstabulation. ANOVA compares mean scores across categories of the independent variable. For this the DV should be measured at the interval level or at the ordinal level when there are a substantial number of categories, as is the case with a summary index.
FURTHER TECHNICAL DETAILS (optional)
- The F-score is calculated as the ratio of between group to within group variances using the figures in Mean Square column of the Anova table. Thus 368.9 divided by .558 = 661.0. This figure is compared to a sampling distribution for F-scores to determine significance. It indicates the number of standard deviations this difference lies from the mean of the sampling distribution. Since roughly two standard deviations (1.96) comprise 95% of the cases, it forms the cut off for the .05 significance level. The F-score here exceeds 661 and thus easily passes significance at the .01 level for the appropriate degrees of freedom.
- Standard Errors = square root of the variance divided by the square root of n (the number of cases for the group). Remember: variance = SD2 .
- The 95% CI for Mean column is calculated by subtracting and adding the 1.96 times the standard error to/from the mean score.
- Derivation of the Sum of Squares and Mean Squares will be discussed later in the term in connection with regression and, if there is time, two-way Anova.
EXAMPLE #2 — Extending the Use of ANOVA
USING ANOVA WITH CROSSTABS:
- After finding a significant relationship in a crosstabulation using Chi-square, it is often also useful to consider which specific columns differ
- A one-way ANOVA provides an efficient approach.
- Technically, ANOVA should be used with a dependent variable measured at the interval level or perhaps with an ordinal level variable with many values such as an index.
- So while you might use the un-recodedversion of an index as a dependent variable with ANOVA, you normally would not use an index in its recoded two, three or four-category form.
- Nevertheless using a recoded form of the dependent variable in an Analysis of Variance will offer some insight as to where the significance differences lie in a crosstabulation using the same variables.
INSTRUCTIONS: (Example #2 )
- After you have found a significant relationship using crosstabulation, try a one-way ANOVA using the same pair of variables.
- Make sure that your dependent variable is at least ordinal, as is typically the case with a recoded index.
- Using a dependent variable recoded into several categories for a crosstabulation, Analysis of Variance will offer insight as to where the significance differences are in the crosstab.
- Be sure to include the Scheffe test for interpretive ease.
Continuing the example from Lab 11 using ANOVA
- Dataset:
- ANES 2012
- Independent Variable:
- Partisan Identification
- Dependent Variable:
- Economic Egalitarian
- Hypothesis Arrow Diagram:
- Party ID → Economic Egalitarian Attitudes
- Syntax (in addition to the syntax from Lab 11)
oneway IEcEq3 by pid /statistics = descriptives /ranges=scheffe /plot means.
- Syntax Legend
- The oneway (anova) command lists the DV and IV
- The /statistics, /ranges and /plot subcommands produce a lot of useful information.
- Note that the recoded form of the index is used here.
- The IV takes on the same values as in the Crosstab. The /statistics, /ranges and /plot subcommands produce a lot of useful information.
- Output
Descriptives
| N | Mean | Std. Dev | Std. Error | 95% Confidence Interval | ||
| Lower Bound | Upper Bound | |||||
| Rep | 1402 | 1.4724 | .72128 | .01926 | 1.4346 | 1.5102 |
| Ind | 1629 | 1.9231 | .80752 | .02001 | 1.8838 | 1.9623 |
| Dem | 1746 | 2.3310 | .72080 | .01725 | 2.2972 | 2.3648 |
| Total | 4777 | 1.9399 | .82758 | .01197 | 1.9164 | 1.9634 |
| ANOVA | |||||
| IEcEq3 | |||||
| Sum of Squares | df | Mean Square | F | Sig. | |
| Between Groups | 573.956 | 2 | 286.978 | 507.951 | .000 |
| Within Groups | 2697.179 | 4774 | .565 | ||
| Total | 3271.136 | 4776 | |||
| Multiple Comparisons | ||||||
| Dependent Variable: IEcEq3 | ||||||
| Scheffe | ||||||
| (I) pid | (J) pid | Mean Difference (I-J) | Std. Error | Sig. | 95% Confidence Interval | |
| Lower Bound | Upper Bound | |||||
| Rep | Ind | -.45068* | .02738 | .000 | -.5177 | -.3836 |
| Dem | -.85859* | .02695 | .000 | -.9246 | -.7926 | |
| Ind | Rep | .45068* | .02738 | .000 | .3836 | .5177 |
| Dem | -.40791* | .02589 | .000 | -.4713 | -.3445 | |
| Dem | Rep | .85859* | .02695 | .000 | .7926 | .9246 |
| Ind | .40791* | .02589 | .000 | .3445 | .4713 | |
| * The mean difference is significant at the .050 level. | ||||||
Means Plot
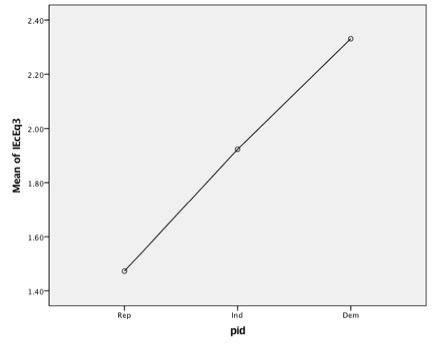
Interpretation
- A quick glance at the Scheffe test results in the Multiple Comparison panel indicates that in terms of Economic Egalitarian Attitudes all three partisan groups differ significantly from each of the other three partisan groups.
- The confidence intervals provide more detail on each two party comparison
- The general hypothesis that “partisan identifiers differ in their egalitarian attitudes” is again supported by the analysis. However the one-way ANOVA test also more specifically shows that Democrats score significantly higher than both Independents and Republicans and that Independents also score significantly higher than Republicans.
QUESTIONS FOR REFLECTION
- Should the results of the one-way ANOVA lead us to rethink, or reconceptualise, the relationship between partisanship and egalitarianism?
DISCUSSION
- Chi-square can tell us whether or not there are significant differences in a cross tabulation, but chi-square alone cannot tell us where those significant differences lie. See, for example, the Canadian Lab 12 for a different pattern of partisan differences and similarities. In situations where more specific differences are also theoretically interesting, we can use one-way ANOVA to examine the data further and more finely tune our findings.